Beyond Ctrl-C: The dark corners of Unix signal handling
Table of contents
RustConf 2024 is next week, so I thought I’d put up a written version of my RustConf 2023 talk about signals in time for that. I’ve tried to retain the feel of it being a talk, while editing it heavily to make it readable as a blog entry. Some links:
- Video of the talk on YouTube.
- Slides on Google Slides.
- Demo repository on GitHub.
1. Introduction#
Imagine you’re in the middle of a conversation, when suddenly, a tap on the shoulder interrupts your train of thought. You turn to face the interloper, only to find a dear friend with an urgent message. In that moment, you’re faced with a choice: do you ignore the interruption and continue your conversation, or do you pause to address your friend’s needs?
In the world of computing, this tap on the shoulder is akin to a signal: a way for the operating system to interject and communicate with a running process. Just as you might choose to ignore or respond to your friend’s interruption, a process must decide how to handle the signals it receives.
Let’s start with a couple of questions:
- Have you ever hit Ctrl-C while running a command-line program?
- Have you ever encountered data corruption because you hit Ctrl-C at the wrong time?
If you’ve answered yes to the second question, then there’s a chance your program isn’t handling signals correctly. Much like a conversation that’s interrupted at an inopportune moment, a process that’s interrupted by a signal can be left in a state of disarray.
In this post, we’ll explore the world of Unix signals, delving into their history and their surprising complexity. We’ll learn how to handle these interruptions gracefully. And we’ll discover how async Rust can help us tame the chaos of signal handling, making it easier than ever to write robust software.
Most of this knowledge comes from my work on cargo-nextest, a next-generation test runner for Rust that is up to thrice as fast as cargo test. One of the things that sets nextest apart is how it carefully, rigorously handles any signals that come its way. Be sure to try it out if you haven’t already!
Why signals?#
If you’re an experienced engineer, you’re probably used to asking questions like why, when, and how much you should care about something.
So: Why bother with signal handling at all? When should you care about signals?
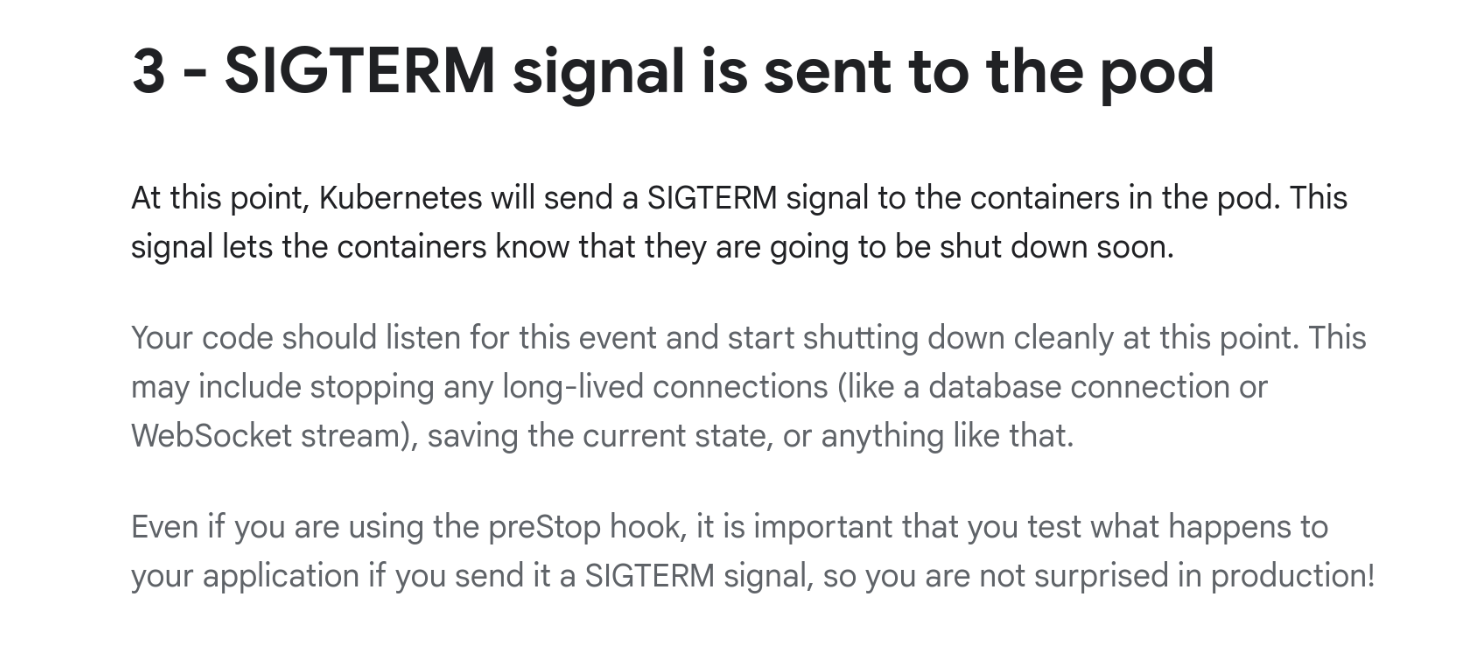
You should care about signals if you’re developing a service. You’re likely going to be running under a service manager like Kubernetes, and the lifecycle generally involves signals.
This screenshot shows Kubernetes documentation explaining that when your service is shutting down, it will receive a
SIGTERM. Docker works the same way withdocker stop.Note how the documentation advises that your code should “listen for this event and start shutting down cleanly at this point”.
You should also care about signals if you’re developing a command-line tool. That’s because your users are impatient and if they perceive your operation as being slow for any reason, they will hit Ctrl-C and send a signal to your process.
How much do you need to care about signals?
If you’re a command like
lsorcatand all you’re doing is reading data, you probably don’t need to care much about signals. You’re not making any changes to the system so there’s little that can go wrong if your process dies.If you’re writing data, it’s definitely worth thinking about signal handling.
There are ways to arrange for your code to be resilient to sudden termination, such as writing files atomically, or using a database like SQLite. But even if your code doesn’t depend on correct signal handling, you can likely provide a better user experience if you do handle them.
Where you need to care most about signals is if you’re orchestrating an operation in a distributed system. In those cases, if the process receives a signal locally, it may wish to send out cancellation messages over the wire.
Again, it’s a good idea to make your system fault-tolerant and resilient to sudden termination—for example, by serializing state in a persistent store—but at the very least, signals give you the opportunity to perform cleanup that can otherwise be difficult to do.
Before we move on: In this post, we’re going to focus on Unix, not Windows. We’re also going to focus on portable signal handling, which means mechanisms that work on every Unix. Some Unix platforms offer alternative ways to handle signals1, but this post will not be discussing them.
A basic example#
Let’s look at a simple example of a signal being sent to a process:
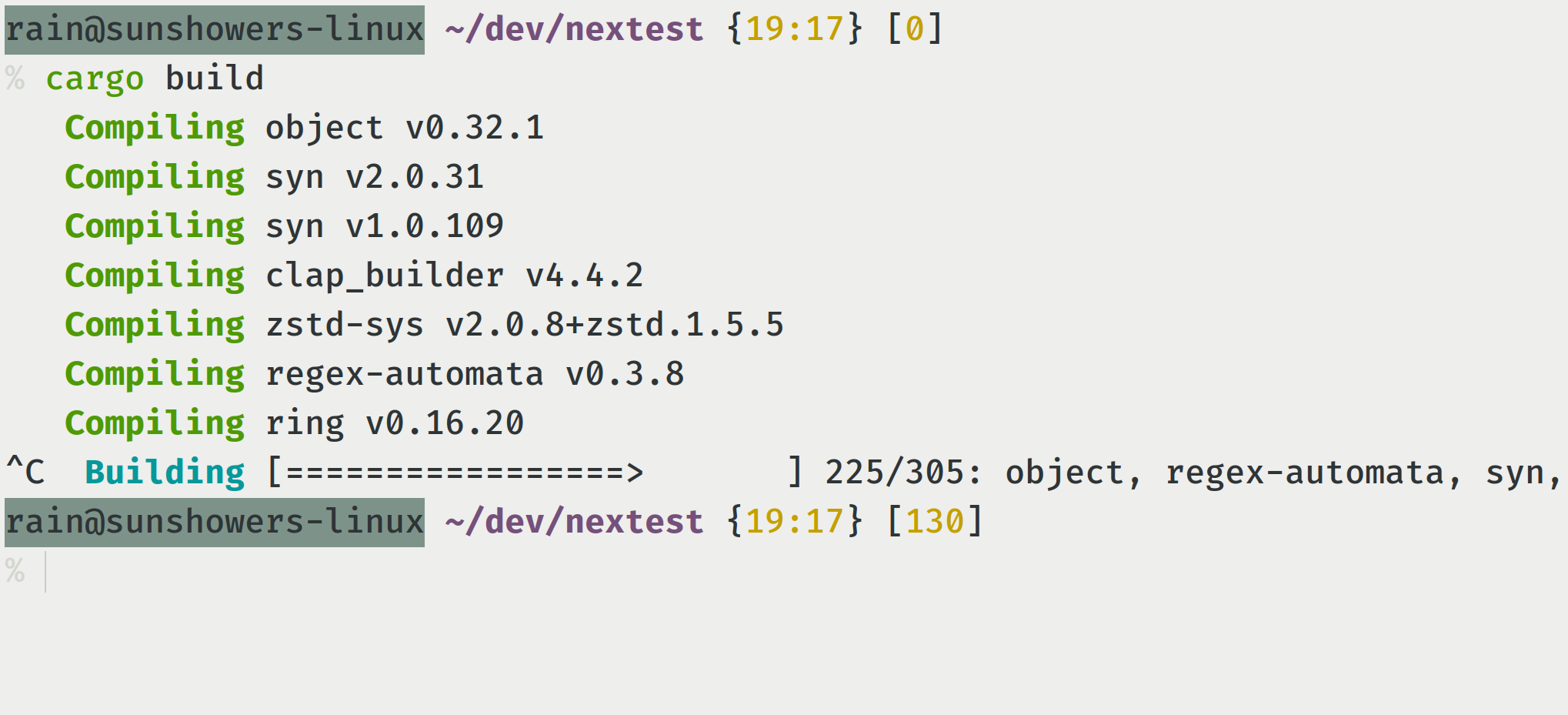
What happened here?
- I ran
cargo build. - Then, a few seconds after, I hit Ctrl-C in my terminal.
- The terminal sent a signal called
SIGINT(whereINTmeans “interrupt”) to the Cargo process. - The
SIGINTsignal caused the Cargo process, as well as all the Rust compiler processes underneath it, to be interrupted and terminated.
This example shows the two uses of signals. One is as a standardized, widely understood way for the kernel to interrupt a process. The other is as a basic, limited way to perform interprocess communication, or IPC.
Sending signals via kill#
Besides Ctrl-C and other shortcuts, the main way you’d be sending signals to processes on the command line is via the kill command.
- To send
SIGINTor Ctrl-C, you can usekill -INT <pid>, where<pid>is the numeric process ID. - Each signal also has an associated number. For
SIGINTthe number is always 2, so another way of saying this iskill -2 <pid>. - If you don’t specify a signal and just say
kill <pid>, it sends SIGTERM by default.
Within a programmatic context, libc has a kill function you can call which does the same thing.
Signal names and numbers#
As mentioned above, each signal has a name and number associated with it. Some of those numbers are standardized across Unix platforms, while others aren’t.
On Linux, if you type in man 7 signal, you’ll see a long list of signals. Some of them are:
| Name | Number | Default action |
|---|---|---|
SIGINT | 2 | Terminate |
SIGTERM | 15 | Terminate |
SIGKILL | 9 | Terminate, can’t customize |
SIGSEGV | 11 | Terminate and core dump |
SIGTSTP | Varies | Stop process |
SIGCONT | Varies | Resume process |
In this table:
SIGKILLis also known askill -9, and it’s a special signal used to kill a process. What setsSIGKILLapart is that unlike almost all other signals, its behavior can’t be customized in any way.SIGSEGVmight be familiar to you if you’ve ever encountered a core dump. Somewhat surprisingly, the behavior ofSIGSEGVcan be customized. For example, the Rust standard library customizesSIGSEGV’s behavior to detect call stack exhaustion2.SIGTSTPandSIGCONTare used for what is called “job control”. If you’ve ever used Ctrl-Z invim, or the commandsfgorbg, then they uses these signals3.
In general, all signals have a default action. Almost all of them also let you customize the default behavior, using what is called a signal handler.
Signal handlers#
A signal handler is a custom function that is used to intercept specific signals. Once a signal handler is set up, the kernel no longer follows the default action, calling the handler instead. In that sense, it’s a reverse system call, also known as an upcall.
For example, if you’re writing or reading data, you use a system call or syscall to perform that action—in that case, you’re calling the kernel. With an upcall, instead, the kernel calls you. (It’s an “upcall” because the call goes “up”, not “down”).
Importantly, signal upcalls can happen at almost any time. And this is where we start running into issues.
2. An example#
To see the sorts of issues that signal handlers can create, let’s walk through a specific example: that of a download manager.
Back in the 2000s, these programs were a lifesaver. I grew up with pretty terrible internet back then, and the download managers had several features that really helped. The most important feature was their ability to resume downloads, something that browsers didn’t support back then.
For this post, we’re going to work with a really simple download manager. Let’s say you provide a bunch of URLs to a tool, which then downloads them in parallel and maintains their status in a database.
Now, let’s say we want to handle SIGINT. If the user hits Ctrl-C, we may want to follow a small set of sensible steps:
- Cancel all running downloads.
- Flush any data to disk.
- In the database, mark the state of these downloads as interrupted.
Your first idea might be, “let’s just put all this logic in a signal handler”. Can you do that? The answer turns out to be that no, you can’t do that. And why you can’t do that is helpful at illustrating many of the pitfalls of signal handlers.
Why are signal handlers limited?#
Earlier, I mentioned that signal handlers can be called at any time. It turns out that the ability to call a piece of code at any time is fraught with peril like little else in computing. This property of signal handlers is at the root of so many of the problems with them.
For example, consider what happens if a signal handler is called while you’re holding a mutex or other lock. In general, trying to acquire the same lock again will result in a deadlock4. So you can’t call functions that try to acquire a lock.
Well, which functions acquire locks? Even something as basic as allocating memory via
mallocrequires a lock, because it pokes at global structures. This means that you cannot allocate memory in a signal handler. This alone shuts off a large percentage of the things you can do in a signal handler.Another joy of signal handling is that while a handler is running, your process can receive a different signal and invoke a second signal handler. As you might imagine, this is just very hard to reason about in practice.
These aren’t just theoretical concerns! You might have heard of the CVE database, where security vulnerabilities are filed and listed. The CVE database has a lesser-known cousin called the CWE database, which lists out “common weaknesses” that result in security vulnerabilities. Within this database, there are no fewer than four weaknesses related to incorrect signal handlers:
- CWE-364: Signal Handler Race Condition
- CWE-432: Dangerous Signal Handler not Disabled During Sensitive Operations
- CWE-479: Signal Handler Use of a Non-reentrant Function
- CWE-828: Signal Handler with Functionality that is not Asynchronous-Safe
On Linux, the man page on signal-safety lists functions described by POSIX as okay to call in signal handlers, and it is pretty short. You can write to a file descriptor, but malloc is not allowed. You also can’t open or seek a file.
The functions okay to call in signal handlers are called async-signal-safe functions. The term is a bit confusing! “async” here has nothing to do with async Rust. (In many ways it’s the opposite of async Rust, because the defining characteristic of async Rust is that you cannot just be interrupted or preempted at any time. You can only be interrupted at await points.)
The self-pipe trick#

So how do most modern programs handle signals? To understand that, we briefly need to introduce the concept of the self-pipe trick. The trick uses a Unix feature called self-pipes, which have been described in the same breath as both “wonderful” and “cursed”: a high honor!
You might be familiar with pipes from having used them in shells via the namesake pipe (|) operator. For example, consider a typical find | xargs command.
- When this command is run, the shell creates a pipe.
- Each pipe has a write end and a read end.
- In the case of
find | xargs, the write end is held byfind, and the read end byxargs.
A self-pipe is just a kind of pipe where the write and read ends are held by the same process.
Now, you might ask, “what’s the point of this?” And you’d be right to do so! Most of the time they don’t add any value. But they do add value in the specific context of signal handlers, because they let programs write signal handlers that are as simple as possible.
- The program starts by creating a self-pipe.
- It then hands the write end of the pipe to a signal handler, and holds on to the read end.
- Then, the signal handler writes to that self-pipe. This is safe to do, because a pipe is a file descriptor, and writing to a file descriptor is async-signal-safe.
- Then, the program reads from the self-pipe elsewhere.
Most C programs do this by hand, but in Rust you don’t have to write this delicate pattern manually. There are several crates which implement this pattern, like signal-hook, and most people just use one of them.
Now what?#
Going back to the download manager example: Let’s say you write to a pipe, indicating that Ctrl-C has been pressed. How do you handle the read side of the pipe? Once you’ve received a signal, how do you handle it?
One option is to set some kind of global flag, and check whether you’ve received a signal at every iteration of a loop–or maybe every Nth iteration of a loop.
This works fine for small programs that are CPU-bound, but isn’t really scalable to large programs because those tend to have lots of loops in them (are you really going to add checks to every loop?)
Large programs are I/O bound anyway, and it’s a bit hard to check for signals while you’re waiting for some network operation to complete.
Another potential solution: Store all the state behind a mutex, and wrest control of the program by locking out all the workers. This is a solution that some programs use, but it is really difficult to coordinate state between the workers and the signal handler. I really wouldn’t recommend following this approach.
The most reasonable approach for I/O-bound programs is to use message passing, where the parts of a program that deal with signals are notified that a signal has occurred.
This is possible to do in a synchronous model, but, as I’ve documented in my previous post about how nextest uses Tokio, it adds a great deal of unbounded complexity. What happens in practice is that you inevitably create a nest of threads whose only responsibility is to pass messages around.
The good news is that dealing with messages is much, much simpler with async Rust.
Why async Rust?#
At this point you might ask: “I’m just a simple downloader tool, why would I need async for this?”
Async Rust is presented as being for massively concurrent web or backend servers, but a secret about it is that that is just marketing. The scope of problems async Rust solves is much broader, and it happens to be incredibly well suited to signal handling for most programs. This is because async Rust provides some very expressive ways to perform advanced control flow, making such code readable without sacrificing performance.
To see how, we’re going to use Tokio’s signal handling functionality, which under the hood uses the same self-pipe trick mentioned above5. Here’s what a very simple example of Ctrl-C looks like under async Rust:
use tokio::signal::unix::{signal, SignalKind};
let mut ctrl_c_stream = signal(SignalKind::interrupt())?;
loop {
ctrl_c_stream.recv().await;
println!("got SIGINT");
}
In this example:
- The code sets up a stream of
SignalKind::interruptor Ctrl-C signals, thenawaiting therecvmethod. - The
recvmethod resolves each time the process receives Ctrl-C.
Now, this isn’t very special by itself; you can easily implement this with synchronous code. But this model really shines in more complex code paths, because of async Rust’s ability to perform heterogenous selects via tokio::select!.
For a detailed discussion of heterogenous selects, see my earlier post about them. But a quick summary is that tokio::select! is a powerful control flow tool that waits for a set of futures to be ready concurrently, and resolves as soon as one of them completes.
What makes tokio::select really special is it doesn’t just work against specific kinds of asynchronicity, but against any arbitrary, heterogenous source of asynchronicity: signals, timers, any async function–you name it. As a result, tokio::select! is a great fit for signal handling6.
Implementing signal handling using tokio::select!#
Going back to our download manager example, let’s try using tokio::select!. There are a few ways to organize this, but here’s one way.
We’re going to briefly introduce two constructs that make our life simpler:
- The
JoinSettype, which stands for a set of worker tasks (not threads!) that are running in parallel. - Broadcast channels, which allows a single producer to send messages to multiple consumers. The idea here is that the main task will receive signals, and then broadcast them to workers.
Here’s how the main function works:
- Create a
JoinSetand a broadcast channel. - Spin up a stream of
SIGINTsignals, as before. - Spawn a task for each worker on the
JoinSet, and pass in a receiver for broadcast messages.
Click to expand code sample
#[tokio::main]
async fn main() {
let to_download = /* ... */;
// Make a JoinSet.
let mut join_set = JoinSet::new();
// Also make a broadcast channel.
let (sender, receiver) = broadcast::channel(16);
// Spin up a stream of SIGINT signals.
let mut ctrl_c_stream = signal(SignalKind::interrupt()).unwrap();
// Spawn a task for each worker, passing in a broadcast receiver.
for args in to_download {
let receiver = sender.subscribe();
join_set.spawn(worker_fn(args, receiver));
}
// ... continued below
}
Next, the main function needs to wait for results from all the workers. How would we do it if we weren’t handling signals? Well, in that case we would loop and wait for each worker task to finish until they’re all done, handling errors along the way.
Click to expand code sample
// continued from above...
loop {
let v = join_set.join_next().await;
if let Some(result) = v {
// Handle result...
} else {
// No more downloads left
break;
}
}
To handle signals, we use a tokio::select! with two branches from which items are fetched in parallel:
- The first branch waits for worker tasks to be done with the same code as above
- The second branch awaits a Ctrl-C message from the stream.
Click to expand code sample
enum CancelKind {
Interrupt,
}
loop {
tokio::select! {
v = join_set.join_next() => {
if let Some(result) = v {
// Handle result...
} else {
// No more downloads left
break;
}
}
Some(_) = ctrl_c_stream.recv() => {
sender.send(CancelKind::Interrupt);
}
}
}
Now let’s look at the worker function. We first write our download function within an async block:
Click to expand code sample
async fn worker_fn(args: Args, receiver: Receiver<CancelKind>) -> Result<()> {
let mut op = async {
args.db.update_state(&args.url, Downloading).await?;
download_url_to(&args.url, &args.file).await?;
args.db.update_state(&args.url, Completed).await?;
Ok(())
};
// ...
}
Then, just like earlier, we write a loop with a tokio::select! over two options:
- The first branch drives the operation forward.
- The second branch waits for cancellation messages over the broadcast channel.
Click to expand code sample
loop {
tokio::select! {
// 1. Drive the operation forward.
res = &mut op => return res,
// 2. Wait for cancellation messages over the broadcast channel.
Ok(message) = receiver.recv() => {
// Handle the cancellation message received.
}
}
}
What makes this model tick is how well it scales up to additional complexity. Two specific examples that are handled well by this model:
- First, you’ll likely want to handle other signals like
SIGTERM, sinceSIGINTisn’t the only signal you’d receive. - Another common extension is to use what is sometimes called a double Ctrl-C pattern. The first time the user hits Ctrl-C, you attempt to shut down the database cleanly, but the second time you encounter it, you give up and exit immediately.
A fully working example of the download manager described above is in the demo repository. These two extensions are marked as exercises for you to complete; try solving them!
3. Going deeper#
If all you’re doing is orchestrating an external operation like downloading files, then this is most of what you need to know. But a lot of the really interesting details about signals lie when you’re spawning processes—such as if you’re a shell, or a test runner like nextest. There is far too much to talk about here, but we’re going to go deeper into one particular example.
Process groups#
In part 1, I mentioned that if you press Ctrl-C, the shell sends SIGINT to the process you’re running. That isn’t quite correct; I fibbed a little! The truth is that the shell actually sends the signal to what is called a process group.
What is a process group? In Unix, processes can be organized into groups, each with its own unique identifier. Process groups allow a set of processes to be sent a signal at once. The shell creates a new process group for the command and its children, assigning them a unique group ID. This allows the shell to manage the processes as a unit, sending signals to the entire group at once.
On Linux, you can print process groups with a command like ps fo pid,pgid,comm. (Other Unix platforms have their own ps flags to display similar output.) For example, if you run this command while cargo build is running in another terminal, you might get some output that looks like this:
$ ps fo pid,pgid,comm
PID PGID COMMAND
1528 1528 zsh
4100 4100 \_ cargo
4261 4100 \_ rustc
4587 4100 \_ rustc
4640 4100 \_ rustc
In this case:
- The
zshshell created acargoprocess numbered4100. - When
zshdid that, it also created a corresponding process group with the same number. - When
cargo buildranrustc, those process groups were inherited.
Recall from earlier that if you want to send SIGINT to a process via the kill command, you’d use kill -INT <pid>.
- If you want to send
SIGINTto a process group, in very typical Unix fashion you have to use a negative number. - For example, if you run
kill -INT -4100, theSIGINTsignal gets sent atomically to the whole process group numbered4100: the process, its children, grandchildren, everything.
And that’s what really happens when you hit Ctrl-C: both the cargo process itself and all the child rustc processes are terminated by this signal sent to the process group.
Making your own process groups#
Let’s say that you’re a test runner like nextest. What if you want to join the party? For example, it’s common for tests to spin up servers in another process to communicate with. A test runner that terminates a test likely also wants to kill off any processes created by that test.

To set the process group for a process, Unix provides a function called setpgid. In Rust, access to this is provided via the CommandExt extension trait’s process_group method.
Most of the time, you’ll want to pass in -1 for the process group, which means that the kernel will create a new process group for you with the same number as the process ID.
Forwarding signals to child process groups#
Let’s say you’re a command-line process that is using process groups to manage its children. What happens if the user hits Ctrl-C?
You might assume that process groups form some sort of tree. Just like with the notion of a tree of processes with parent and child processes, you might imagine that process groups follow a similar pattern.
In reality: no, process groups don’t form a tree. Each process group is its own island.
This means that as a boundary process which manages process groups of your own, it is your responsibility to forward signals to child process groups.
(This is quite easy to fit into our async Rust model: the worker tasks, on receiving a broadcast message, send the corresponding signal to the process groups that they’re responsible for.)
Most programs would want to behave as similarly as possible to the world where they didn’t set up process groups. To achieve that you’ll want to at least forward these signals:
To match behavior, for signals that are typically sent to process groups:
SIGINT(Ctrl-C).SIGQUIT(Ctrl-\).SIGTSTP(Ctrl-Z), andSIGCONT(fgorbg).These two signals are interesting to handle in nextest: if you have timers running for your processes, for example if you want to timeout and kill process groups, you can combine
SIGTSTPandSIGCONTwith async Rust to pause and resume those timers. (There is also a deep story about an issue in POSIX lurking here, which I’ll cover in a sequel to this post.)
Also consider, to meet user expectations, forwarding SIGTERM and other signals. These signals are not always sent to process groups, but it would make sense to forward them.
4. Conclusion: echoes of the past#

Signals are a fundamental part of the computing landscape, a legacy of design decisions made decades ago. They are a reminder that the systems we build today are shaped by the choices of the past, and that even the most well-intentioned innovations can have unintended consequences.
In the words of Doug McIlroy, creator of Unix pipes:
Signal()was there first and foremost to supportSIGKILL; it did not purport to provide a sound basis for asynchronous IPC. The complexity ofsigaction()is evidence that asynchrony remains untamed 40 years on.
Signals, for all their utility, were never meant to be the foundation of interprocess communication that they have become today. Yet we have found ways to adapt and evolve them to our needs, working around their limitations and turning them into opportunities.
Indeed, this is the essence of computing, and of technology itself: a story of creativity in the face of constraint, and of building upon the foundations of the past to create something new and beautiful.
I hope this post has shed some light on the fascinating world of Unix signals, and perhaps even inspired you to think closely about the systems you build. If you’ll be at RustConf in Montreal, come find me: I’d love to chat more about this and hear your own stories about signals, or of other intricate systems with long-forgotten design decisions. See you there!
Thanks to Fiona for reviewing a draft of this post.
One example is signalfd on Linux. There is much to be said about signalfd, but it is outside the scope of this post. ↩︎
Some other language runtimes do much, much worse things with
SIGSEGV. Here’s what Java does. ↩︎If you haven’t, by the way, check it out! It’s one of the cooler parts of Unix. ↩︎
If you’ve dealt with locks you might have heard of the concept of recursive or re-entrant locks, which are locks that can be acquired by the same thread as many times as desired. Recursive locks often indicate a design flaw, because the goal of a lock is to temporarily violate invariants that are otherwise upheld outside of its context.
But more importantly, it isn’t guaranteed that signal handlers are going to be called on the same thread! So even recursive locks might deadlock when it comes to signal handlers. ↩︎
Under the hood, Tokio uses mio, which uses a self-pipe for its portable implementation. But on some platforms such as Linux, mio uses eventfd. This is an extension to Unix that is quite similar to self-pipes, and from the perspective of signal handlers serves the same purpose. ↩︎
There’s a case to be made that
tokio::select!is too freeform—too powerful. By hiding details about async cancellation,select!can lead to surprising bugs. See this blog post by boats for more.In this example, we’re handling cancellation explicitly, so the impact of those issues is less direct. ↩︎